In the years 2003-2011, I worked for a pure technology service provider, NDS (acquired by Cisco in 2012, then later became Synamedia) which was considered at the time, the world leader in end-to-end digital TV software systems. I was fortunate enough to experience as an engineer every major area of platform development for this complex ecosystem; and then later as a software manager, I would own the software delivery for a core piece of the software stack known as "middleware", for NDS's primary anchor customer BSkyB/Sky Darwin and then later would own the full stack delivery of NDS's flagship Mediahighway Fusion/Unity product. This experience would mark my entry into very complex large-scale technology delivery initiatives, which even to this day, thirteen years later, as I work with the world's largest cloud provider, Amazon AWS, in building out its enterprise cloud support systems (AWS Support Center / Technical contact systems), Fusion still takes the prize for the most intense professional experience, learning and growth, technical complexity, risk and high-stakes projects. So yeah, I find myself having to dig deep into my memory to recall this work experience because it's funny that 13 years on, I'm encountering the same topics of engineering management even though it is supposed to be a different domain, turns out "software is just software"!
NDS had captured almost every top-tier PayTV operator around the globe at the time: Sky, DirecTV, UPC, Sky Italia, Sky Deutschland, Foxtel, Sky LA, Yes, Bharti, etc. NDS was prominently known for its conditional access product, a video content protection system call NDS Videoguard, however, NDS offered more than just security and offered customers a fully vertically integrated ecosystem (think "Apple" ecosystem for PayTV customers). Whilst digital TV was built on open standards and interoperability, most customers limited their integration points. So when they opted for NDS as their security provider, they also had the option of integrating all other services - from broadcast backend services in the headend to consumer device hardware development and software service integration with chipset vendors. The consumer device software was known as TV Middleware. At the time, the main players were NDS Mediahighway, OpenTV & TiVo. NDS was known for convincing customers to migrate to NDS Mediahighway, its technology migration programs were demanding, complex and executed flawlessly. As an engineer, I contributed software to replace TiVo, an overnight win for 40 million devices. Later as a software delivery manager for the Sky Darwin migration project, we would replace OpenTV software almost obliterating its presence from Sky, save for a few ancient, ageing hardware profiles.
NDS, with an increasing number of customers using its security, middleware and application services, couldn't afford to scale out with engineering teams for each custom build. A platform strategy was needed, consolidating the best of software from across the globe (US, UK, India, Israel, France) into a new shared technology stack, that offered flexible customisation and tailoring for any type of customer profile (Tier-1 customers like Sky for advanced applications to Tier-3/4 customers in territories just starting off with basic digital TV), using a shared engineering resource pool - and extensible configuration engine for producing tailored custom releases. So was borne, NDS Mediahighway Fusion.
The flagship customer for Fusion was Sky, which went live in 2010, replacing up to ten variants of its consumer device software services, with new Fusion components and Sky's own custom-developed consumer application "EPG" known then as the "Orchid EPG". Fusion provided an SDK/API for customers to develop their own primary applications, along with an interactive HTML engine, that allowed PayTV operators to add additional mini apps to their devices, like games and weather apps. With Sky being the anchor customer, Fusion had proved itself in the market and thus was ready to onboard new customers like Sky Italia, UPC, Foxtel, Yes, etc. Post Darwin launch, I took the lead for building the new platform vision, called Fusion Snowflake EPG through project Sunrise - birthing the platform that would create customer, tailorable configurations for any customer, maximising reuse and minimising customisation but allowing for a selection of custom user experiences.
Why am I claiming Fusion as large-scale (even in 2023, 13 years later)?
I write this in 2023, after spending 2.5 years with Amazon AWS. I am part of the group that build AWS Support Center and related Contact Center services. We are a team of under 100 people, deemed large- scale and building complex systems. Yet, if I have to be brutally honest with myself, I'm mildly impressed by my exposure to date, because my current work pails in comparison to my work on Fusion, 13 years ago. Yes I know it's a different domain, a different paradigm and culture of Amazon's 2-Pizza team model for software product ownership (which I actually find quite cool)...still I'm finding it hard to rationalise my move to AWS almost 2.5 years on, have I gone too far backwards? Am I living too much in the past & not ready to view things from a new perspective? What am I not seeing? (Topics for another post). So whilst I've defintely adapted my mental models since joining Amazon, yet I really can't ignore some software engineering truths which is the reason for my bringing up the past now.
In 2012, I wrote the first story about Fusion, introducing the term LSSDP I coined to mean Large Scale Software Development Project. I also dived deep, writing lengthy white papers about the product and engineering management processes:
- How we "scaled agile" to adapt to our unique global challenges
- How to design a global org-structure to deliver a large-scale project in a scaled agile way
- What mechanisms are needed to deliver a large-scale technology initiative in an agile way
- How we executed and raised the engineering & product management bar
Fast forward to 2023, now using my Amazon AWS experience as a lens for defining a large-scale initiative and indirectly checking engineering manager role guidelines for large-scale:
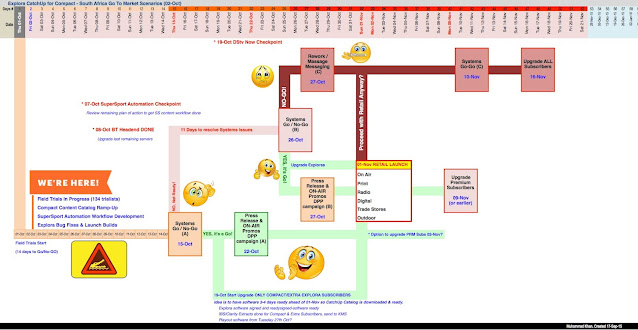
- Business Impact - Fusion started off with a $75 million investment and later a joint-venture with the flagship customer, Sky. The entire company pivoted to focus on Fusion as its next-generation software platform, with up to 3000 engineers world-wide working on multiple streams, some strategic foundational streams kicked off at least 2 years before the mainstream program. In my role as software delivery owner for Sky Darwin project, it was critical the project delivered successfully, flawlessly - as it involved migrating software in 10 million people's homes (their living room TVs) seamlessly with no rollback. To the end customer (the person sitting at home watching TV), they would notice very little change to their experience. Overall, Fusion software components delivered to multiple middleware stacks, at the time of 2011 when I departed NDS, our software was running in excess of 60 million people's homes daily, globally.
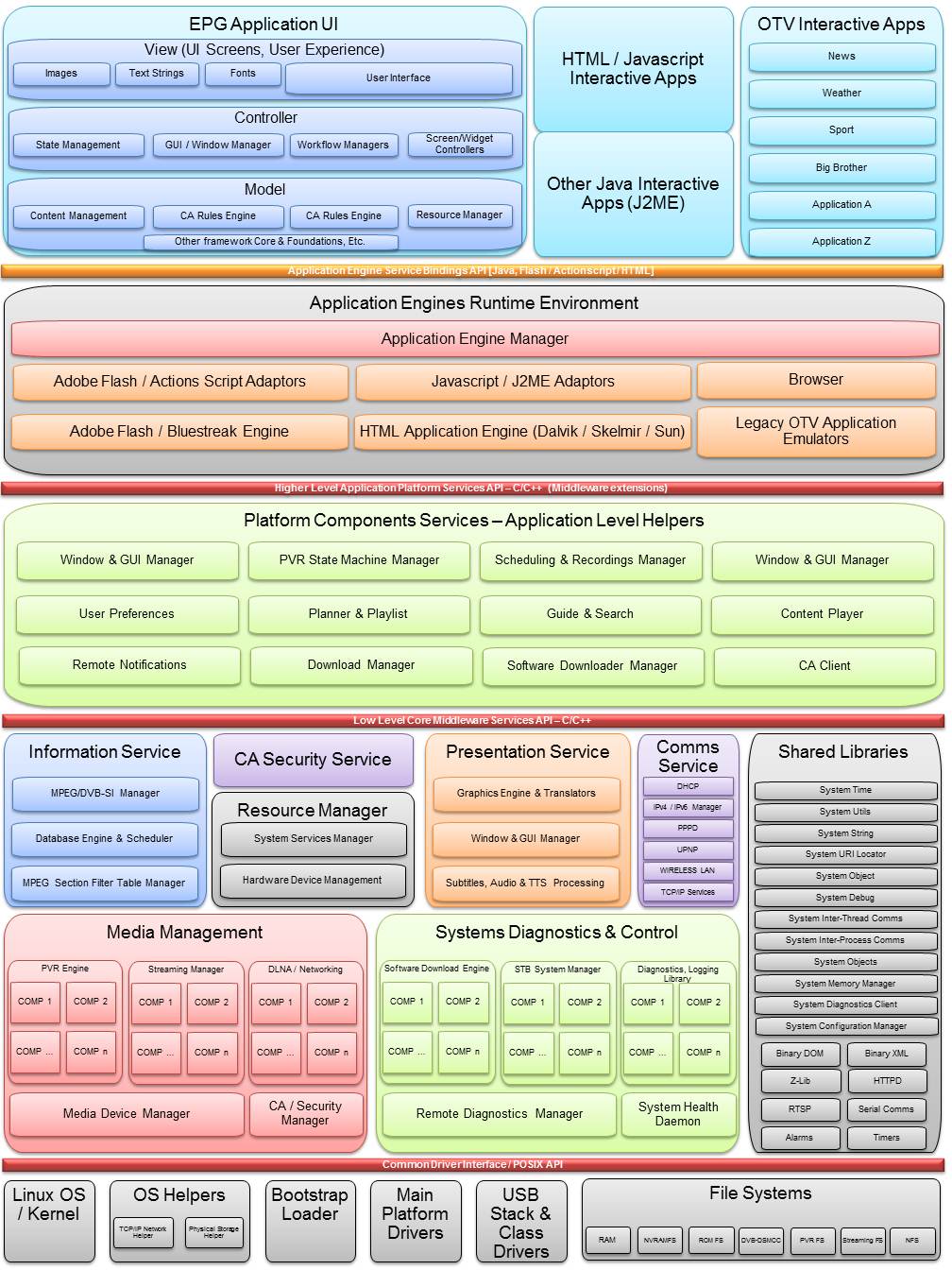
- Scope and Size - Fusion introduced a new paradigm of the TV software ecosystem, end-to-end, including broadcast headend components as well as embedded software architecture. The stack was open, based on a Linix/Posix and a complete departure from the initial decade of TV software operating systems. This was before the advent of Android TV or fully open source middleware. Fusion's product backlog captured over 2000 epics in the form of work packages, cutting across multiple customer needs, in parallel. The scope included all layers of the device software stack: Chipset drivers, hardware absraction layer, Linux kernel, Linux abstraction, Middleware services, Application SDK/APIs, multiple frontend application engine proxys for C / C++ / Java / HTML / Flash applications. Take a look at the software architecture diagram - it is multi-layered, multiple service teams. Another point on scope, we managed initiatives or epics in the form of work pacakages (WPs), that could impact up to 25 service teams in one WP, see here.

























{kind=link}