In my previous post, I discussed the model we used for Product Management in the context of a Large-Scale SW Development project that involved the design & development of a complex STB Middleware stack, a User Interface Application (EPG) and a full System Integration activity. Recall the development was spread across multiple countries & multiple locations, the Middleware Stack itself was component-based broken up into around eighty independent software components (or modules) that was also owned by a distributed team, this team was at least constant of 200 people, at peaks the project scaled to have around 350 people working on it.
In this post, I will share the Development, Integration, Test & Delivery Model we adopted for that project, that became the foundations for all future projects. I believe the essence of this method is alive to this day to this day, getting close to 5 years now, with incremental evolutionary enhancements added.
Disclaimer 0
The experiences I'm writing about is about past projects that are very much in the public domain:
BSkyB replacing OpenTV HDPVR with NDS technology
Fusion is the new NDS Mediahighway to displace OpenTV
BSkyB Launches new HDPVR
Sky Italia replacing OpenTV HDPVR with NDS Mediahighway
Sky Deutchland delivers enhanced VOD powered by NDS Mediahighway
UPC being powered by NDS MediaHighway
Background on why I can write about this stuff
My role on the BSkyB/Fusion project as Technical Project Manager, a.k.a. in some places as "Development Owner" for the full Middleware Stack, working closely with the Architects, Integrators, Testers, Project Managers, SW Development Managers as well as Senior Management in all four countries UK (2 sites), France, Israel & India (2 sites). I was involved in all activities associated with Planning & Delivery, Architecture, Development, Integration, Operation Field Trials and General Logistics & Co-ordination support. It required a strong technical hat, I had to understand the software architecture in fair amount of detail to hold technical conversations with the Architects & Component Owners, as well as sometimes coaching and guiding people through technical issues that were critical to the project. I was also involved in configuration management discussions around branching / merging and release planning. I ran all types of meetings necessary for managing the project; I would also sit on customer calls to review defects, agree on the components responsible, sometimes bypassing defect triage or characterisation process. I would also review defect severities and priorities, often re-aligning them with project priorities. I also supported the development and integration teams in planning component deliveries and producing the release plan and delivery release schedule to System Integration. It was a multi-faceted role that I quite enjoyed since it brought into play all my previous experiences of STB UI & Middleware Development, Headend Development & Integration; as well as Development Management giving me the broad expertise and versatility required to contribute positively to the project. I stayed long enough to take the project to its major milestone of being ready for external field trials, then left the project before it finally launched 3 months later, to work on new projects (since the processes were in place, ticking along and could do without me)...Some people have fed back that I'm a good starter/initiator of things, but not a complete finisher - I've done both, however my history does show that I tend to leave just at the right moment, having been immersed into the project to climb the steep mountain, and on reaching the climax, start extracting myself out to work on other new & exciting ventures...When BSkyB/Darwin was launched, I went on to the overall Fusion Product Management team where we centrally coordinated and managed the new projects that were pending on BSkyB's success: Sky Italia, UPC, Sky Deutchland and Internal Product roadmap enhancements. All Fusion projects had to adopt the development methodology pioneered on Fusion/Darwin, the role of the central Product team was to ensure the integrity of the established processes were adopted and maintained for all ongoing and new projects...
Disclaimer 1
Remember this is just my recollection of a project that was done in the years 2006-2010 (started in 2006 but gained critical mass from 2008-2010), so a lot may have changed since then that I'm not privy to since I'm no longer working at that company (I left the mainstream Middleware Product team toward the end of 2010, then exited company altogether in early 2011 primarily for personal/family reasons, to relocate back to South Africa after a living & working for a decade in Europe).
Remember this is just my recollection of a project that was done in the years 2006-2010 (started in 2006 but gained critical mass from 2008-2010), so a lot may have changed since then that I'm not privy to since I'm no longer working at that company (I left the mainstream Middleware Product team toward the end of 2010, then exited company altogether in early 2011 primarily for personal/family reasons, to relocate back to South Africa after a living & working for a decade in Europe).
This post is split into the following areas:
- Recap the Product Management Process
- Architecture Background into Component Development & Integration Process
- Configuration Management Patterns - Best Practices Adopted
- Integration Streams Overview
- Development Streams Overview
- Overview of Work Package Development & Integration Concepts
- Walkthrough of WP Development Stream
- Work Package Integration & Delivery Walkthrough
- Managing Work Package Deliveries - Landing Order Process
- Continuous Integration & Test Philosophy
- Feature Delivery & Release Management: Branch & Release Philosophy
- Conclusions
In the previous post I shared the model around product management, the theme being iterative, functional development and testing, adopting most of the Agile philosophies. I've had some feedback from Agile/Scrum experts on that post, I plan to share this feedback in the last piece of this series, the concluding post (stay tuned). In a nutshell then, we instrumented a rather detailed, prioritised Product Backlog that broke down the work in the form of Work Packages. Each Work Package (WP) on the backlog identified the Components impacted, and the various owners involved in developing, integrating, testing and delivering the WP. The WP itself followed a structured process of Requirements, Design, Implementation, Test Planning, Integration & Test & Delivery stages - all executed within the context of a time-boxed iteration, being 6 working weeks, or 30 day sprints. Much of the pre-planning and initial design was done prior to the start of the Iteration, the aim being to start development on day one of the iteration. The iteration was actually shared between development & integration: Work Packages (WPs) were targeted to complete no later than the end of the third week (15th day) of the iteration, to allow for Integration Testing the following two weeks, with the sixth and final week reserved for stabilisation and critical bug fixing. The aim for each WP was to ensure Functionality Complete with Zero Regression (We tried to stay true to the values of Scrum as best as we could). Whilst this may sound like a Waterfall process within the iteration itself, there were a lot of parallel, continuous collaboration between the various teams - Integration actually did happen in parallel with development, with continuous feedback as well.
A WP would impact one or more components, the size of the WP varied from two components (not necessarily considered a simple WP as this depended on the components impacted) to 20 components (a complex WP based on the amount of integration effort involved). We had a few massive WPs involving change across the full stack complement (80 components), but these were few and far between. As the architecture solidified, massive changes across the stack was a rare occurrence. A single component would typically be impacted in at least ten work packages simultaneously that needed to be delivered in the current iteration. As the source code is shared for the same component, component owners had to main a very strict coordination of the development changes required in the iteration - there would be common functions touched by each WP, which contributed to complicated merge scenarios.
The process did not allow for combining WPs together, we were strict in adhering to a WP is a single entity that delivers a unit of functionality targeted for a specific feature, needed to be isolated and almost atomic, such that it's becomes a manageable and relatively low risk process to revert a WP delivery due to serious regressions. Thus components were not allowed to merge code of other WPs - we maintained a strict delivery order. There were exceptions to this rule of course, but the aim was to make the occurrence of these incidents extremely rare. We counted on our architects doing the due diligence required to ensure collaboration between various other projects were maintained (since we were effectively developing a product to sell to multiple customers and markets, there were more than one project active at the time, with the development team all working off the same product code base). So some WPs were grouped where it made architectural and practical sense to do so.
There were also some WPs or features that were quite difficult to implement piecemeal on a WP-by-WP basis, even though the theory and process called for breaking down the work such that each WP is doable in an iteration, there were some functionality, for example around complex PVR scenarios that required a long lead development on a branch, almost independent to the main development stream. We called these "Functional Subtracks" or FSTs, where a special team was set up to work autonomously, on a separate track (a sub-track) to get the job done. FSTs were still tracked on the Product Backlog and WPs were broken down, but from my end, it was just administration and no active management involvement. An FST Owner was allocated to run with the FST, a sub-project, a separate work stream, independently project managed from start-to-finish. Overall synchronisation and co-ordination with the parent project was still mandatory, because we had very strict configuration management rules in place, for example: it was mandatory the FST code was refreshed every week and merged with the master code, to prevent a massive attempt at merging back to the central code-base when the FST was deemed complete. FSTs themselves executed on a sprint-by-sprint basis, incrementally delivering on the required functionality.
Finally, if you want to recap the process visually, the time line template below captures most of the above discourse:
A WP would impact one or more components, the size of the WP varied from two components (not necessarily considered a simple WP as this depended on the components impacted) to 20 components (a complex WP based on the amount of integration effort involved). We had a few massive WPs involving change across the full stack complement (80 components), but these were few and far between. As the architecture solidified, massive changes across the stack was a rare occurrence. A single component would typically be impacted in at least ten work packages simultaneously that needed to be delivered in the current iteration. As the source code is shared for the same component, component owners had to main a very strict coordination of the development changes required in the iteration - there would be common functions touched by each WP, which contributed to complicated merge scenarios.
The process did not allow for combining WPs together, we were strict in adhering to a WP is a single entity that delivers a unit of functionality targeted for a specific feature, needed to be isolated and almost atomic, such that it's becomes a manageable and relatively low risk process to revert a WP delivery due to serious regressions. Thus components were not allowed to merge code of other WPs - we maintained a strict delivery order. There were exceptions to this rule of course, but the aim was to make the occurrence of these incidents extremely rare. We counted on our architects doing the due diligence required to ensure collaboration between various other projects were maintained (since we were effectively developing a product to sell to multiple customers and markets, there were more than one project active at the time, with the development team all working off the same product code base). So some WPs were grouped where it made architectural and practical sense to do so.
There were also some WPs or features that were quite difficult to implement piecemeal on a WP-by-WP basis, even though the theory and process called for breaking down the work such that each WP is doable in an iteration, there were some functionality, for example around complex PVR scenarios that required a long lead development on a branch, almost independent to the main development stream. We called these "Functional Subtracks" or FSTs, where a special team was set up to work autonomously, on a separate track (a sub-track) to get the job done. FSTs were still tracked on the Product Backlog and WPs were broken down, but from my end, it was just administration and no active management involvement. An FST Owner was allocated to run with the FST, a sub-project, a separate work stream, independently project managed from start-to-finish. Overall synchronisation and co-ordination with the parent project was still mandatory, because we had very strict configuration management rules in place, for example: it was mandatory the FST code was refreshed every week and merged with the master code, to prevent a massive attempt at merging back to the central code-base when the FST was deemed complete. FSTs themselves executed on a sprint-by-sprint basis, incrementally delivering on the required functionality.
Finally, if you want to recap the process visually, the time line template below captures most of the above discourse:
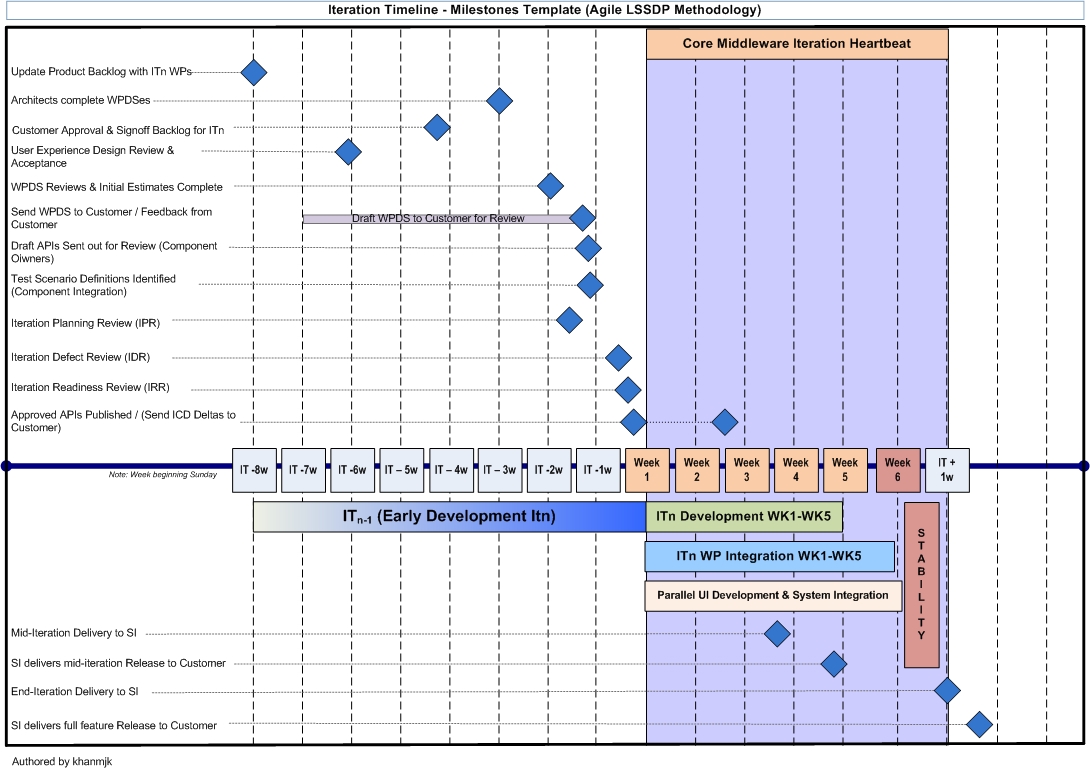 |
| Overview of the Product Development/Integration Model |
To appreciate why we ended up with a very controlled Development & Integration process, one has to first understand the type of software stack we were building. I've searched high and low to find public references to the Middleware Stack we created, but unfortunately, this is either not publicly available or very hard to find. So I've reconstructed the architecture model from memory (I made it a point to by-heart the architecture to help me better manager the project, but I was also exposed to the architecture in its fledgling design stage as I hacked some POCs together) as I understood it at the time (I plan to expand on the architecture model in a future post, but this will have to do for now) shown below:
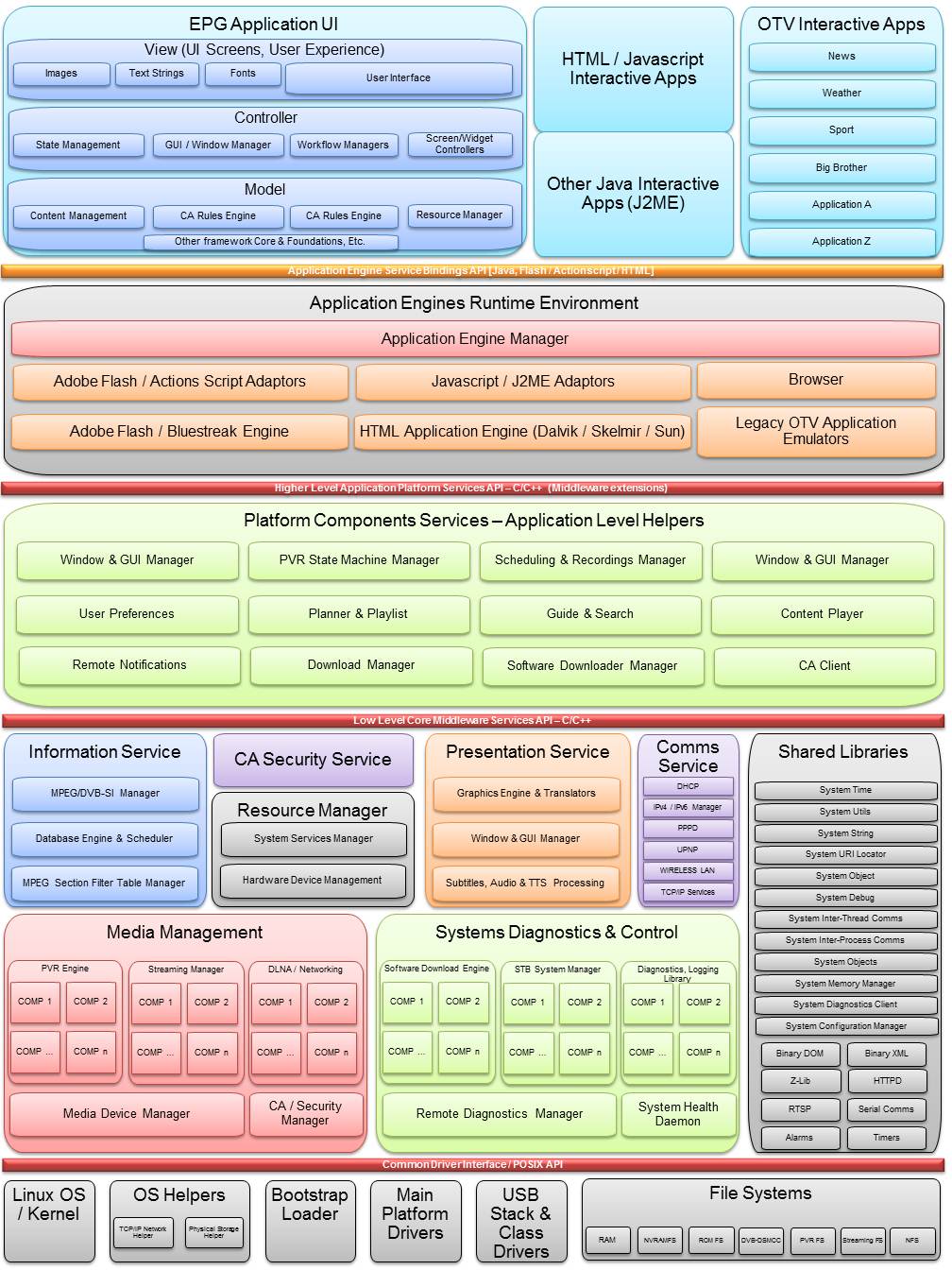 |
| Generic Logical Representation of a STB Software Stack |
Take for example, the Information Services group. This component-group logically implements the STB's ability to parse the broadcast stream, populate an event and service information database, maintain updates to the database as the broadcast stream is required, and provide an information services interface to upwards and sidewards components that depend on this API. An example of an upwards API is the User Interface (EPG) that needs to display the information about a program currently being played, the actor details and a 3 or 4 line description of the program itself (called the Event synopsis). A sidewards component, say the PVR manager needs to know when a program's start & end time is to trigger a recording.
So component-group integration would entail testing the flow internally between the child components implementing the information services components, and exercising all paths of the APIs exposed. Digging deeper, the information services group would consist of a database component, example, a fully fledged SQL Lite database, or a McObject database, or a proprietary implementation. Nevertheless, that fundamental component will be subject to component unit testing primarily, but if there were APIs exposed elsewhere, for example, a Query API for Read/Writing to the database, then that'll call for Component Integration tests.
The same can be said for a PVR or Media Streaming logical area - which is by the most complicated piece of the software stack. The PVR engine consists of internal components, not all of them can be independently tested since a device pipeline is required. So the PVR engine will export its own test harness that tests the group, and expose the API required to exercise it.
Thus the Middleware stack is a complex mixture of an array of components. Development and Integration therefore was a closely coupled activity, although implemented by two very separate teams: a Development team and an Integration team.
The Development team typically owns a Logical group of components and was split between the different countries UK, Israel, France & India based on the core strengths of the teams. Remember this was our sixth or seventh evolution of the Middleware product, with each country owning a certain level of speciality and competence. Each country had effectively either written Middleware products before, or major components there-of, so organisationally the ownership for the Middleware stack had to be spread across the various countries, but maintaining a focus to leverage on the key competencies of the various regions.
The Integration team were no different to the Development team, apart from not owning components, but instead owned the Middleware Test Harness software stack - this in itself can be considered a product in its own right. The integration team were basically made up of software engineers, who had to understand the component APIs down to the code level, and also were required to debug component code. Integration therefore was a low-level technical activity, ensuring that test cases were applied as close as possible to realise customer user experiences by driving through the component APIs. The Middleware Test Harness (MTH) tested both depth and breadth of middleware functionality by using the published APIs through executing test cases - all in the absence of the EPG. This was truly component-based testing. Once confidence was achieved through the Middleware Test Harness, we were more confident that implementing client application with the Middleware would be relatively painless, since the functionality had already be exercised through the MTH. Suffice to say, we had to rely heavily on automated testing, which I'll cover in the section on Continuous Integration & Testing.
Recap Quality Critera
Before I delve deeper into the mechanics of the process, it is good to recap the component quality constraints that we were obligated to deliver upon as you'll begin to appreciate why the production process had to be tightly governed (for more exhaustive detail on the quality criteria, read here):
- Must have a Component Requirements Specification Document
- Each component requirement must map into a high level Product Use Case
- Must be testable
- Requirements-to-test-mapping matrix document
- Automatic component unit tests must cover component requirements
- 100% Test coverage of Requirements-to-tests
- Must be testable in isolation - component unit test
- Must be testable in a group - component group testing
- Must be testable as a subsystem - Middleware tests
- Must be testable as a system - full stack system tests
- Test results be attached to release notes per release
- Must have no Regressions - 100% Component Tests Must Pass
- Must have an up-to-date API Interface Control Document
- APIs must be testable and map to a component requirement
- Higher level APIs must map to high level product use cases
- Must have a Component Design Specification Document
- Must have an Open Source Scan Summary Report
- Must have Zero Compiler Warnings
- Must have Zero MISRA Warnings
- Must exercise API coverage 100%
- Must test Source Code Branch Coverage, results at least 65%
- Must test Source Code Line Coverage, results at least 65%
By now you should realise that this process called for very solid Configuration Management practices. We had settled for Rational ClearCase as the tool of choice, and adopted much of the Rational UCM terminology for Software Configuration management. The actual implementation of ClearCase was the distributed model where we had servers distributed in each location, so called "Local Masters" in two sites within the UK, one in Paris, Jerusalem and two sites in Bangalore, whilst the central "Grand Master" site located in UK. With the multi-site version suited for globally distributed development we had to contend with synchronisation and replication challenges as with any distributed system, and the constant challenge of aligning time zones. Suffice to say, we had a separate, globally distributed team just for managing the ClearCase infrastructure-and-administration alone.
If I get a chance some time, I'll try to dig into the details of this particular type of Configuration Management (CM) System, but there are plenty of examples online anyway....but for the purposes of this post, I'll have to define some basic terms that I'll use throughout this post on taking you through the Work Package Workflow. Note this is as I understood them at 50000 feet so please forgive my deviations from pukka UCM terminology! (Click here for full glossary on IBM site):
This is illustrated by the following graphic below:
Overview of Work Package Development & Integration
Now that we've covered the basics around the CM system and the concept of Work Packages (WPs), it's time to illustrate how we executed this, from a high level. Of course there were many situations around development/integration one encounters that calls for other solutions, but we always tried to maintain the core principles of development & integration, which can be summarized as:
Walkthrough of WP Component Development Stream
Component A seems like quite a core component as it's impacted in all four Work Packages (WPs). This means that the team has to plan their work not only according their own internal team constraints, but also have to match the project's plan for the iteration, such that the delivery order is observed: WP2 delivers first, then WP3, followed by WPs 1 & 3. In parallel, Component A has got some severe quality problems in that its not reached the required branch coverage, line coverage and MISRA count - and this team has to deliver not only on the WPs planned, but also meet the quality target, for the release at the end of the iteration. There is the other challenge, that probably due to scheduling challenges, or the complexity of the work, this team has to start all WP development off on the same day. So in addition to the separate, yet parallel quality stream, the team works on the WP requirements on four separate WP development streams.
Component teams largely implemented Scrum, they maintained internal sprint backlogs that mapped to the overall project iteration plan. So Comp A would have planned in advance the strategy for doing the development, plan in code review points, sync points, etc. Note though, that it was often frowned upon to share code between WP streams if the WP hadn't delivered yet. This is so that the Integrators only tested the required features of the said WP, without stray code segments from other WPs that wouldn't be exercised by the defined integration tests. Remember that Integrators actually exercised component source code through their defined public interfaces as specified in the Work Package Design Specification (WPDS).
Component A then has to maintain careful synchronization of changes, essentially aiming to stay close to component tip to inherit latest code quality improvements, and then co-ordinating the rebase when the WP delivery happens. When Integration give the go-ahead for delivery, Comp A creates a candidate baseline, having rebased off Tip, for the WP stream. Integration then applies final testing on the candidate baselines of all components impacted, and if there are no issues, components create the release baseline (.REL) in UCM-speak, and post the delivery to Grand Master. Looking at the example shown for Comp A, when WP2 delivers to GM, this means all the code for WP2 is effectively pushed to component tip. This automatically then triggers a rebase of all child WP streams to inherit the latest and merge with tip, so WP3,4,1 will immediately rebase and continue working on their respective WP streams until it's their turn for delivery. So there is this controlled process of rebase to tip, deliver, rebase, deliver....
The same applies for Component E, although it is much more simple - since Comp E only works on delivering just two WPs, WP1 & WP4. And according to this team, WP1 starts first, followed by WP4 - the rebase and merge happens when WP1 delivers, followed by WP4 delivery.
There are many different scenarios for component development, each component presented it's own unique challenges. Remember this mentality is all about working on different streams impacting common files and common source code, for example, the same function or API might be impacted in all four work packages, so internal team co-ordination: fundamental.
To close this section on development stream, note that at each point in the delivery or even rebase point, component teams had to comply with all testing requirements, so at each point in the delivery chain, the CI system was triggered to run automated tests...
Walk through of the WP Integration Stream
The figure above shows the Integration Stream on the bottom right-hand corner, illustrating the Grand Master Stream along with the regional Local Masters, with their child WP Integration streams. It also shows, in similar vein to the component stream, the activities involved with WP delivery to Local Master, and ultimate delivery into the Grand Master (GM).
Looking at WP4, which impacts all the components, we can see that component development streams feed into the WP integration stream. What happens is the following: At the start of the iteration, which marks the end of a previous iteration where a release baseline was produced off GM, all Local Masters (LM) will have rebased to the latest GM. Once the LMs have rebased, Integrators from the various regions will have created WP Integration streams for all WPs planned for that iteration. The Integrator uses that WP stream to put an initial build of the system together, and starts working on his/her Middleware Test Scenarios. Test Scenarios are test cases implemented in source code that uses the Middleware Test Harness Framework. This framework is basically a mock or stubbed Middleware, that can be used to simulate or drive many of the Middleware APIs. For a WP, the components will have published all their API changes before hand, publish the header file in advance and provide stubbed components (APIs defined but not implemented) to the Integrator. The Integrator then codes the test scenarios, ensuring the test code is correct, works with component stubs until all components deliver into the WP stream with the implemented functionality.
The integrator does a first pass run, removes the stub components replacing them with the real components and begins testing. If during testing, Integrator uncovers issues with the components, components will deliver fixes off that components WP stream. This process is collaborative and repeats until the Integrator is happy that the core test scenarios are passing. In parallel, the components have run their own component unit testing and code quality tests, and are preparing for the call to candidates from the Integrator. The Integrator runs Middleware Core Sanity and other critical tests, then calls for candidates from the components. Depending on the severity of the WP, the Integrator might decide to run a comprehensive suite of tests off the CI system, leave the testing overnight or over the weekend to track major regressions - if all is well and good, the components deliver releases to the WP stream (this is usually the tip of the component).
Some co-ordination is required on the part of the Integrator. Remember there are multiple WPs being delivered from various Integration locations. Nearing completion of his/her WP, the Integrator broadcasts to the world, makes an announcement that "Hey, my WP4 is ready for delivery, I need a slot to push my delivery to Master". This then alerts the global product integration team, just like an air traffic controller would look out for other planes wishing to land, of other WPs in the delivery queue, takes a note of the components impacted, then allocates a slot for the WP in the delivery queue.
If there were other projects with higher priority that preempted WP4 delivery, then the integrator has to wait, and worst case has to rebase, re-run tests, call for candidate releases again, re-run regression tests, and then finally deliver to Master.
Overview of WP Delivery Order process
A discussion on Distributed Development & Integration cannot be complete without discussing the resulting Delivery challenges. I touched on this subject above, in terms of how the four example work packages would deliver back to GM based on the Delivery Order for the iteration. I also mentioned that this activity mapped to Air Traffic Controller, maintaining strict control of the runways landing order.
During the early stages of the programme where it was just BSkyB and SkyD, the number of Work Packages (WPs) delivering within the iteration (recall we had 6 weeks iteration, 5 weeks reserved for development & integration, 6th week reserved for stability bug fixes, WPs were not allowed in the 6th week), would average around 25 WPs. At peak times, especially when we had a strong drive to reach the feature complete milestone, we'd have around 50 WPs to deliver, I recall a record of 12 or 15 WPs delivered on just one day, with hardly any regression!
Of course, when we were pushed, there were times that called for management intervention to just go ahead and deliver now, and sort regressions out later: Just get the WP in by the 5th week, use the weekend and the 6th week to fix regressions. This case was the exception, not the norm.
When BSkyB launched, we had a backlog of other customer projects with the same urgency as BSkyB, if not more urgent - and with higher expectations of delivering some complex functionality within a short, really short timeline. By the second half of 2010 we had at least 3 major customer projects being developed simultaneously, all off the common Grand Master codebase - this called for extreme control of GM deliveries.
We had on average 45 WPs planned for each iteration. We had introduced more components to the middleware stack to support new features. We also introduced new hardware platforms for each customer (will cover this under a later CI section)...
To manage the planning of GM deliveries we had to create what we called the GM Delivery Landing Order. One of my tasks on the Product Management team was to ensure the GM Delivery plan was created at the start of the iteration. Customer project managers would feed their Iteration WP plans to me, highlighting all the components impacted, and estimated Integration complete date, along with Integration location. Collecting all these plans together, we then created a global delivery schedule. Of course there were obvious clashes in priorities between projects, between WPs in projects, Components within projects and cross project interdependencies that all had to be ironed out before publishing the GM Delivery plan. The aim of the GM delivery plan was to ensure a timetable was baselined and published to the global development and integration teams. This timetable would show which WPs belonging to which projects were delivering on which day, from which integration location, and the estimated landing order. Once the iteration started, I had to maintain regular updates to the plan as most of the time, WPs would slip from one week to another, or brought forward, so the GM delivery plan had to sync up with latest changes.
We had a dedicated team of Integration Engineers for the Product Team that co-ordinated and quality controlled the deliveries to GM. They relied heavily on this published GM delivery schedule as they used it to drive the landing order for WPs on the day. The GM Delivery Lead would send out a heartbeat almost every hour, or as soon as WPs were delivered to refresh the latest status of the landing order.
I could spend a good few pages talking about the intricacies of controlling deliveries - but by now you should get the drift. Take a look at the following graphic that summarizes most of the above.
If I get a chance some time, I'll try to dig into the details of this particular type of Configuration Management (CM) System, but there are plenty of examples online anyway....but for the purposes of this post, I'll have to define some basic terms that I'll use throughout this post on taking you through the Work Package Workflow. Note this is as I understood them at 50000 feet so please forgive my deviations from pukka UCM terminology! (Click here for full glossary on IBM site):
- Stream - Basically a branch for individual development / integration work, automatic inheritance of other streams
- Baseline - A stable, immutable collection of streams, or versions of a stream
- Project - Container for development & integration streams for a closely related development/integration activity
- Rebase - Merge or synchronisation or touch point with latest changes from a chosen baseline
- Delivery - The result of merging or pushing any changes from one stream into another stream
- Tip - The latest up-to-date status of the code/baseline from a particular stream
At the highest level, we have a Configuration Management (CM) system that implemented Rational's UCM process. We had a CM team that defined the architecture and structure for the various projects, basically everyone had to adopt the CM's team's policy (naming conventions, project structure, release & delivery processes). Our project was under full control of the Middleware Integration team. This team defined the rules for component development, integration and delivery. Whilst component development teams had freedom to maintain their own component projects under CM, they had to satisfy the CM and Integration rules for the project - and this was controlled by the Integration team.
Integration therefore maintained the master deliverable for the product. This was referred to as the Grand Master, or Golden Trunk or Golden Tree. Integration was responsible for product delivery. Integration owned the work package delivery. Integration was therefore King, the Gate Keeper, the Build Master, nothing could get past Integration! This was in keeping with best practices of strong configuration management and quality software delivery. The primary reason for this strong Integration process was to maintain a firm control of Regression. We focused more on preventing regression over delivering functionality, in some cases we had to revert code deliveries of new features, just to maintain an acceptable level of regression. Integration actually built the product from source code; so much so that Integration controlled the build system, makefile architecture for the entire product. Development component owners had to just fall in line. Rightly so, we had a core group of about four people responsible for maintaining the various build trees at major component levels: Drivers, Middleware, UI & full stack builds. Components would deliver their source tree from their Component streams into Integration stream. Integration also maintained a test harness that exercised component code directly. This build and configuration management system was tightly integrated with a Continuous Integration (CI) system that not only triggered the automatic build process but also triggered runs of automated testing, tracking regressions and also went to the extent of auditing the check-ins from various component development streams, integration streams, looking for missed defects, as well as defects that went in that wasn't really approved by Integration.....gasp for breadth here....the ultimate big brother maintaining the eye on quality deliveries.
In essence, we implemented Promotional-based pattern of SCM.
Sample of References on SCM practices supporting our choice of best practice SCM
In essence, we implemented Promotional-based pattern of SCM.
Sample of References on SCM practices supporting our choice of best practice SCM
Software Configuration Management Patterns: Effective Teamwork & Integration
SCM Blog on Agile Branches & Streams
October 2007 Coding Horror piece on Branches & Parallel Universes
A paper on advanced branching strategies
Another paper on parallel development strategies
Overview of Our Integration Streams
SCM Blog on Agile Branches & Streams
October 2007 Coding Horror piece on Branches & Parallel Universes
A paper on advanced branching strategies
Another paper on parallel development strategies
Overview of Our Integration Streams
The figure below is a high level illustration of what I described earlier. It highlights the distributed model of CM, illustrating the concepts of maintaining separation of the Grand Master (GM) from localized Development/Integration streams, showing also the concept of isolated Work Package (WP) streams. Summarizing again: Component Development and Delivery was isolated to separate WP streams. The WP stream was controlled by Integration. Depending on where the bulk of the WP was implemented, since WPs were distributed by Region, the WP would deliver into the local master. From the local master, subject to a number of testing and quality constraints (to be discussed later), the WP will ultimately be delivered to GM.
 The figure above shows an example where ten (10) WPs are being development, and distributed across all the regions. The sync and merge point into GM required tight control and co-ordination, so much so that we had another team responsible for co-ordinating GM deliveries, producing what we called "GM Delivery Landing Order", just as an Air Traffic Controller co-ordinates the landing of planes (more on this later...).
The figure above shows an example where ten (10) WPs are being development, and distributed across all the regions. The sync and merge point into GM required tight control and co-ordination, so much so that we had another team responsible for co-ordinating GM deliveries, producing what we called "GM Delivery Landing Order", just as an Air Traffic Controller co-ordinates the landing of planes (more on this later...).
The figure also highlights the use of Customer Branches that we created only when it was deemed critical to support and maintain the customer project leading up to launch. Since we were building a common Middleware product, where the source code was not branched per customer, needed did it contain customer-specific functionality or APIs, we maintained strict control over branching - and promoted a win-win argument to customers that they actually benefit by staying close to the common product code, as they will naturally inherit new features essentially for free! Once the customer launched, it becomes a prerogative to rebase to GM as soon as possible to prevent component teams from having to manage unnecessary branches. To do this we also had a process for defect fixing and delivery: Fixes would happen first on GM, then ported to branch. This ensured that GM always remained the de-facto stable tree with latest code, thus giving customers the confidence that they will have not lost any defect fixes from their branch release when merging or rebasing back to GM. This is where the auditing of defect fixes came into the CI/CM tracking.
Also shown in the figure above is the concept of FST stream as I highlighted earlier. Basically an FST is a long lead development/integration stream reserved for complex feature development that could be done in relative isolation of the main GM, for example, features such as Save-From-Review-Buffer or Progressive Download component, or Adaptive Bit-Rate Streaming Engine - could all be done off an FST and later merged with GM. As I said earlier, FSTs had to be regularly rebased with GM to maintain healthy code, preventing massive merge activities toward the end.
Overview of Component Development Streams

The figure also highlights the use of Customer Branches that we created only when it was deemed critical to support and maintain the customer project leading up to launch. Since we were building a common Middleware product, where the source code was not branched per customer, needed did it contain customer-specific functionality or APIs, we maintained strict control over branching - and promoted a win-win argument to customers that they actually benefit by staying close to the common product code, as they will naturally inherit new features essentially for free! Once the customer launched, it becomes a prerogative to rebase to GM as soon as possible to prevent component teams from having to manage unnecessary branches. To do this we also had a process for defect fixing and delivery: Fixes would happen first on GM, then ported to branch. This ensured that GM always remained the de-facto stable tree with latest code, thus giving customers the confidence that they will have not lost any defect fixes from their branch release when merging or rebasing back to GM. This is where the auditing of defect fixes came into the CI/CM tracking.
Also shown in the figure above is the concept of FST stream as I highlighted earlier. Basically an FST is a long lead development/integration stream reserved for complex feature development that could be done in relative isolation of the main GM, for example, features such as Save-From-Review-Buffer or Progressive Download component, or Adaptive Bit-Rate Streaming Engine - could all be done off an FST and later merged with GM. As I said earlier, FSTs had to be regularly rebased with GM to maintain healthy code, preventing massive merge activities toward the end.
Overview of Component Development Streams
The Component Tip, just like the Grand Master (GM) represents the latest production code common to all customer projects for that component. Work Package development happens on an isolated WP Development Stream, that delivers to an Integration WP Stream. When the WP is qualified as fit-for-purpose, only then does that code get delivered or merged back to tip. At each development stream, CI can be triggered to run component-level tests for Regression. Components also maintain customer branches for specific maintenance / stability fixes only. Similarly FST stream is created for long-lead development features, but always maintaining regular, frequent rebases with tip.
This is illustrated by the following graphic below:
 |
| Overview of a Development Teams CM Structure |
Now that we've covered the basics around the CM system and the concept of Work Packages (WPs), it's time to illustrate how we executed this, from a high level. Of course there were many situations around development/integration one encounters that calls for other solutions, but we always tried to maintain the core principles of development & integration, which can be summarized as:
- Isolated development / integration streams regardless of feature development / defects fixes
- Where defects impacted more than one component with integration touch-points, that calls for a WP
- Controlled development and delivery
- Components must pass all associated component tests
- Integration tests defined for the WP must pass, exceptions allowed depending on edge-cases and time constraints
- Deliveries to Grand Master or Component Tip tightly controlled, respecting same test criteria outlined earlier
The next picture aims to illustrate what I've described thus far. It is a rather simplified, showing the case where four WPs (identified as WP1...WP4) are planned, showing the components impacted, the number of integration test scenarios defined as acceptance criteria for each WP, along with the planned delivery order.
 |
| Overview of Work Package Develpment / Integration streams |
In this example I've highlighted just five Components (from a set of eighty), and just four WPs (in reality, we had on average 30 WPs for an iteration, with an average of six-to-eight components impacted in a typical WP). Also shown is the location of each integration region, remember we were doing globally distributed development. So WP1 made up of Components A, B, D, E would be integrated and delivered from London UK, WP2 with Components A, C integrated from Paris, WP3 Components D, B, A, C from India and WP4 with Components A-E integrated and delivered from Israel. What's not shown however is that each component was also in itself distributed (which challenged integration because of regional time differences)...
Walkthrough of WP Component Development Stream
Component A seems like quite a core component as it's impacted in all four Work Packages (WPs). This means that the team has to plan their work not only according their own internal team constraints, but also have to match the project's plan for the iteration, such that the delivery order is observed: WP2 delivers first, then WP3, followed by WPs 1 & 3. In parallel, Component A has got some severe quality problems in that its not reached the required branch coverage, line coverage and MISRA count - and this team has to deliver not only on the WPs planned, but also meet the quality target, for the release at the end of the iteration. There is the other challenge, that probably due to scheduling challenges, or the complexity of the work, this team has to start all WP development off on the same day. So in addition to the separate, yet parallel quality stream, the team works on the WP requirements on four separate WP development streams.
Component teams largely implemented Scrum, they maintained internal sprint backlogs that mapped to the overall project iteration plan. So Comp A would have planned in advance the strategy for doing the development, plan in code review points, sync points, etc. Note though, that it was often frowned upon to share code between WP streams if the WP hadn't delivered yet. This is so that the Integrators only tested the required features of the said WP, without stray code segments from other WPs that wouldn't be exercised by the defined integration tests. Remember that Integrators actually exercised component source code through their defined public interfaces as specified in the Work Package Design Specification (WPDS).
Component A then has to maintain careful synchronization of changes, essentially aiming to stay close to component tip to inherit latest code quality improvements, and then co-ordinating the rebase when the WP delivery happens. When Integration give the go-ahead for delivery, Comp A creates a candidate baseline, having rebased off Tip, for the WP stream. Integration then applies final testing on the candidate baselines of all components impacted, and if there are no issues, components create the release baseline (.REL) in UCM-speak, and post the delivery to Grand Master. Looking at the example shown for Comp A, when WP2 delivers to GM, this means all the code for WP2 is effectively pushed to component tip. This automatically then triggers a rebase of all child WP streams to inherit the latest and merge with tip, so WP3,4,1 will immediately rebase and continue working on their respective WP streams until it's their turn for delivery. So there is this controlled process of rebase to tip, deliver, rebase, deliver....
The same applies for Component E, although it is much more simple - since Comp E only works on delivering just two WPs, WP1 & WP4. And according to this team, WP1 starts first, followed by WP4 - the rebase and merge happens when WP1 delivers, followed by WP4 delivery.
There are many different scenarios for component development, each component presented it's own unique challenges. Remember this mentality is all about working on different streams impacting common files and common source code, for example, the same function or API might be impacted in all four work packages, so internal team co-ordination: fundamental.
To close this section on development stream, note that at each point in the delivery or even rebase point, component teams had to comply with all testing requirements, so at each point in the delivery chain, the CI system was triggered to run automated tests...
Walk through of the WP Integration Stream
The figure above shows the Integration Stream on the bottom right-hand corner, illustrating the Grand Master Stream along with the regional Local Masters, with their child WP Integration streams. It also shows, in similar vein to the component stream, the activities involved with WP delivery to Local Master, and ultimate delivery into the Grand Master (GM).
Looking at WP4, which impacts all the components, we can see that component development streams feed into the WP integration stream. What happens is the following: At the start of the iteration, which marks the end of a previous iteration where a release baseline was produced off GM, all Local Masters (LM) will have rebased to the latest GM. Once the LMs have rebased, Integrators from the various regions will have created WP Integration streams for all WPs planned for that iteration. The Integrator uses that WP stream to put an initial build of the system together, and starts working on his/her Middleware Test Scenarios. Test Scenarios are test cases implemented in source code that uses the Middleware Test Harness Framework. This framework is basically a mock or stubbed Middleware, that can be used to simulate or drive many of the Middleware APIs. For a WP, the components will have published all their API changes before hand, publish the header file in advance and provide stubbed components (APIs defined but not implemented) to the Integrator. The Integrator then codes the test scenarios, ensuring the test code is correct, works with component stubs until all components deliver into the WP stream with the implemented functionality.
The integrator does a first pass run, removes the stub components replacing them with the real components and begins testing. If during testing, Integrator uncovers issues with the components, components will deliver fixes off that components WP stream. This process is collaborative and repeats until the Integrator is happy that the core test scenarios are passing. In parallel, the components have run their own component unit testing and code quality tests, and are preparing for the call to candidates from the Integrator. The Integrator runs Middleware Core Sanity and other critical tests, then calls for candidates from the components. Depending on the severity of the WP, the Integrator might decide to run a comprehensive suite of tests off the CI system, leave the testing overnight or over the weekend to track major regressions - if all is well and good, the components deliver releases to the WP stream (this is usually the tip of the component).
Some co-ordination is required on the part of the Integrator. Remember there are multiple WPs being delivered from various Integration locations. Nearing completion of his/her WP, the Integrator broadcasts to the world, makes an announcement that "Hey, my WP4 is ready for delivery, I need a slot to push my delivery to Master". This then alerts the global product integration team, just like an air traffic controller would look out for other planes wishing to land, of other WPs in the delivery queue, takes a note of the components impacted, then allocates a slot for the WP in the delivery queue.
If there were other projects with higher priority that preempted WP4 delivery, then the integrator has to wait, and worst case has to rebase, re-run tests, call for candidate releases again, re-run regression tests, and then finally deliver to Master.
Overview of WP Delivery Order process
A discussion on Distributed Development & Integration cannot be complete without discussing the resulting Delivery challenges. I touched on this subject above, in terms of how the four example work packages would deliver back to GM based on the Delivery Order for the iteration. I also mentioned that this activity mapped to Air Traffic Controller, maintaining strict control of the runways landing order.
During the early stages of the programme where it was just BSkyB and SkyD, the number of Work Packages (WPs) delivering within the iteration (recall we had 6 weeks iteration, 5 weeks reserved for development & integration, 6th week reserved for stability bug fixes, WPs were not allowed in the 6th week), would average around 25 WPs. At peak times, especially when we had a strong drive to reach the feature complete milestone, we'd have around 50 WPs to deliver, I recall a record of 12 or 15 WPs delivered on just one day, with hardly any regression!
Of course, when we were pushed, there were times that called for management intervention to just go ahead and deliver now, and sort regressions out later: Just get the WP in by the 5th week, use the weekend and the 6th week to fix regressions. This case was the exception, not the norm.
When BSkyB launched, we had a backlog of other customer projects with the same urgency as BSkyB, if not more urgent - and with higher expectations of delivering some complex functionality within a short, really short timeline. By the second half of 2010 we had at least 3 major customer projects being developed simultaneously, all off the common Grand Master codebase - this called for extreme control of GM deliveries.
We had on average 45 WPs planned for each iteration. We had introduced more components to the middleware stack to support new features. We also introduced new hardware platforms for each customer (will cover this under a later CI section)...
 |
| Plane Landing Order Queue for Heathrow Airport |
{kind=link}
We had a dedicated team of Integration Engineers for the Product Team that co-ordinated and quality controlled the deliveries to GM. They relied heavily on this published GM delivery schedule as they used it to drive the landing order for WPs on the day. The GM Delivery Lead would send out a heartbeat almost every hour, or as soon as WPs were delivered to refresh the latest status of the landing order.
I could spend a good few pages talking about the intricacies of controlling deliveries - but by now you should get the drift. Take a look at the following graphic that summarizes most of the above.
 |
| Grand Master WP Deliveries Dashboard (For One Sample Iteration) |
 |
| GM Timetable: WPs from Each LM, Timeline for whole Iteration |

Continuous Integration (CI) & Testing is the bedrock of any Agile Development process, more so when you apply the strong configuration management patterns as described above. Reinforcing the need for a very strong CI system was our quality criteria that was equally applied at all levels of Development / Integration & Testing. Refer to an earlier section in this post is a summary of the code quality constraints or search this blog for "Quality" as I've written extensively on this topic before.
Continuous Integration & Testing
Throughout this post I touched on the theme of Continuous Integration (CI) & Testing. Having chosen the Promotional Branch/Integration pattern that supports multiple parallel development & integration streams, especially with the core aim of keeping the Grand Master stable with most up-to-date features, that approach called for a strong testing approach, which is essentially Continuous Integration (CI).
CI by default implies automatic builds, in fact, automatic building shouldn't even be called CI, if you don't have associated automatic tests that get triggered at the point of building. There are many levels off testing involved, throughout the software stack. Regardless off where a component is in the software stack, with CI, a component must be testable. This is typically done through unit testing component source code. The standard practice of Test-Driven-Development calls for writing test code first, before writing the functional code... In the context of our STB Software stack, there are many worlds of testing. We applied the component-based test approach, in keeping with the logical nature of the STB software stack as shown earlier. The essence of this testing approach is conveyed in the figure below:
The layers of onion analogy is often applied to software architecture. In the same vein, the testing follows the layered approach, where each layer (architectural group or component grouping) can be tested in isolation. As long as APIs were exposed, the components were testable. We could therefore independently and discreetly test the following components of the stack, building one layer upon the another, starting from platform drivers all the way up to the full STB stack:
We virtually eliminated the need for Manual Testing the Middleware
Have a look at the architecture diagram again: Between the CDI interface and the Application Engine Adaptors interface, lies the hear of the Middleware Stack. The Public API exposed by the Middleware therefore had to support a number of application domain platforms: C/C++-API for native applications requiring best performance/efficiency, Java Adaptors, Adobe Flash Adaptors and HTML4/5 Adaptor interfaces. Adaptors were meant to be kept as thin as possible, just providing the pass-through translation of the core-API to higher-level code APIs. Adaptors that exposed business logic that was still generic and consistent with most PayTV business models were pushed down to the Middleware Platform Services layer, which provided plug-ins and other interfaces to swap between different rules, example: PayTV operators are notorious for not following the preferred MPEG/DVB protocols for Service List Management, from the initial scanning to building up the Service List, to how they deal with logical channel number ordering and grouping. It also is different depending on the DVB profile in use: DVB-S/S2, Terrestrial, Cable and to some extent IP. But from a high-level perspective, the Middleware must provide a generic service for Scanning in the Core Services API, and expose plug-ins that implement the business rules at Platform Services Layer, ultimately exposing specific domain deviations at either the Adaptor layer, or within the UI application code itself.
Of course, this was the ideal - but in some cases we couldn't satisfy everyone, some adaptors were more heavy than others, and the application development could not afford to wait for the perfect implementation of Middleware patterns and so took it upon themselves to work around some of the Middleware limitations in the Adaptor layer, but always taking a note of the workaround on the Product Backlog - so we don't forget about it (Adaptors must remain thin and pure).
Although I've deviated from script here and touched on architecture topics, it is actually relevant to the discussion around the scope of Middleware Testing / QA:
We did NOT rely on a separate UI application to drive and prove the Middleware, we relied more on the discreet Middleware Test Harness that exercised the APIs just before the Adaptors. We did not have a separate QA team that tested in a separate test cycle - All testing was done continuously and completed at the end of the Iteration - where we always had a Release to ship to customer. Variability and dependence on lower dependent components was eliminated through the process of stable promotion points (e.g. Platform drivers always stable, pre-proven and promoted prior to current Middleware Test). The same applied for Application Testing (always performed on the last stable, promoted Middleware Stack).
Adaptors themselves would implement unit tests and used in conjunction with UI testing by stubbing out the Middleware. Full Stack testing the end-to-end functionality was ultimately a System Integration responsibility not the Middleware test team's responsibility - All the Middleware had to do was prove the Middleware component was fit-for-purpose through the Test Harness, which was available to customers and application providers to use.
At the Driver / Platform level Interface, the Common-Driver Interface (CDI), we also had a separate Test Harness that also eliminated the need for manual testing (we got pretty close to it). The CDI was much broader than the Middleware because the CDI actually became standard in most customers, even those legacy customers not using Fusion Middleware, instead used HDI (Hardware Driver Interface). HDI was replaced by CDI, as it paved the way to migrating to Fusion in future. So CDI had a customer base much wider than Fusion Middeware, around 30+ platforms. Platforms were therefore subjected to independent testing at CDI, and before promoting to Fusion project, had to be integrated with a known stable GM baseline, pass the acceptance criteria, before merging with mainstream projects.
So our testing strategy relied heavily on discreet testing of features and functionality using various test harnesses depending on which layer was tested. Every Work Package (WP) had an associated Test Specification. The Test Specification consisted of the standard Test Plan which is a collection of Test Scenarios written in plain English to direct the WP Integrators on how to test. Associated every test case is a Technical Streams Specification. This streams specification specifies details of Transport Stream requirements to test the particular test scenario, yes, we hand-crafted bit-streams for each test scenario. Of course some test cases required execution on live stream, but we also had the facility of recording the live broadcast from each night, especially if there's regression on a certain build where test scenarios failed on live, we could go back to that particular date/time and replay that particular broadcast (I think we kept up-to-two weeks old live captures)...The CI system hooked up with the Middleware Test Harness and supplied a control interface to play out bit streams. So when automatically executing a test scenario, one of the first steps was to locate the associated bitstream required for the test, wait for a bitstream player resource to become free, start the bitstream player, wait for a sync point and then execute the tests.
Our Middleware Test Harness had around 1500 tests which were mostly automated, with a few manual tests that stood around 150-200 (it was difficult to simulate Progressive Download environment or a Home Networking setup at the time). This gave us confidence in repeatable, deterministic test cases with a reproducible test environment. This method removed the dependence on having a separate Middleware QA test team, traditionally performing manual testing using some application to drive the Middleware. It was all about solidifying the Middleware Component itself, integrate an application, if some feature was not working, it was most likely an Application error rather than a Middleware error.
All of this was possible through a carefully applied management process, powered by an awesome Continuous Integration platform...
And Finally, I bring thee Continuous Integration: the Mother-of-All CI Systems...

CI by default implies automatic builds, in fact, automatic building shouldn't even be called CI, if you don't have associated automatic tests that get triggered at the point of building. There are many levels off testing involved, throughout the software stack. Regardless off where a component is in the software stack, with CI, a component must be testable. This is typically done through unit testing component source code. The standard practice of Test-Driven-Development calls for writing test code first, before writing the functional code... In the context of our STB Software stack, there are many worlds of testing. We applied the component-based test approach, in keeping with the logical nature of the STB software stack as shown earlier. The essence of this testing approach is conveyed in the figure below:
 |
| Worlds of Testing |
- Platform Drivers / HAL / CDI Test Harness - Tests not only the CDI Interface, but exercises functionality of the platform as if there was a Middleware driving the hardware
- Middleware Test Harness - Exercised all the APIs and cross-functionality exposed by the 80+ components making up the Middleware component. Components themselves being testable by:
- Component-unit testing - As outlined earlier, not only were components subject to code quality criteria, every API and other internal functions had to be fully testable: Public & Private API. Public APIs were exposed to other Middleware components, Private APIs within the component itself, i.e. a Component like a Service Information Manager SIM) would actually consist of multiple internal modules or sub-components, each module exposing a private API within the SIM namespace.
- Component-Group testing: Required where a chain of components combined together realises a desired functionality. For example the PVR manager or Streaming Engine relied on other Device Manager components to set up the device chains to get media content input, translated and manipulated -- this is all done independent of the parent Middleware, in isolation
- Application Test Harness - Tests the UI application using stubs of the Middleware API, by simulation. During integration this would be with the real Middleware component, subject to the Middleware component passing the quality criteria and being promoted for integration with UI.
- Full Stack Testing - tests the full stack of components, the last layer
With this layered approach to architecture and testing, it also allows for the breadth/depth of testing to reduce as you go higher up the stack. This is illustrated by the pyramid in the above diagram. Through automation/CI, we achieved maximum benefit of testing, that we could eliminate the need for manual testing across the stack. With test harnesses at each layer, we build confidence that layers underneath has been sufficiently exercised through their respective integration and unit testing harnesses.
All this testing happens through the CI system. The CI system is triggered on events of a new software build is available, be it a component build, a Middleware stack build or a full system integration build. Our CI system was tightly integrated with ClearCase and followed the streams concept. In essence any stream could be run on the CI system, depending on bandwidth of course.
We virtually eliminated the need for Manual Testing the Middleware
Have a look at the architecture diagram again: Between the CDI interface and the Application Engine Adaptors interface, lies the hear of the Middleware Stack. The Public API exposed by the Middleware therefore had to support a number of application domain platforms: C/C++-API for native applications requiring best performance/efficiency, Java Adaptors, Adobe Flash Adaptors and HTML4/5 Adaptor interfaces. Adaptors were meant to be kept as thin as possible, just providing the pass-through translation of the core-API to higher-level code APIs. Adaptors that exposed business logic that was still generic and consistent with most PayTV business models were pushed down to the Middleware Platform Services layer, which provided plug-ins and other interfaces to swap between different rules, example: PayTV operators are notorious for not following the preferred MPEG/DVB protocols for Service List Management, from the initial scanning to building up the Service List, to how they deal with logical channel number ordering and grouping. It also is different depending on the DVB profile in use: DVB-S/S2, Terrestrial, Cable and to some extent IP. But from a high-level perspective, the Middleware must provide a generic service for Scanning in the Core Services API, and expose plug-ins that implement the business rules at Platform Services Layer, ultimately exposing specific domain deviations at either the Adaptor layer, or within the UI application code itself.
Of course, this was the ideal - but in some cases we couldn't satisfy everyone, some adaptors were more heavy than others, and the application development could not afford to wait for the perfect implementation of Middleware patterns and so took it upon themselves to work around some of the Middleware limitations in the Adaptor layer, but always taking a note of the workaround on the Product Backlog - so we don't forget about it (Adaptors must remain thin and pure).
Although I've deviated from script here and touched on architecture topics, it is actually relevant to the discussion around the scope of Middleware Testing / QA:
We did NOT rely on a separate UI application to drive and prove the Middleware, we relied more on the discreet Middleware Test Harness that exercised the APIs just before the Adaptors. We did not have a separate QA team that tested in a separate test cycle - All testing was done continuously and completed at the end of the Iteration - where we always had a Release to ship to customer. Variability and dependence on lower dependent components was eliminated through the process of stable promotion points (e.g. Platform drivers always stable, pre-proven and promoted prior to current Middleware Test). The same applied for Application Testing (always performed on the last stable, promoted Middleware Stack).
Adaptors themselves would implement unit tests and used in conjunction with UI testing by stubbing out the Middleware. Full Stack testing the end-to-end functionality was ultimately a System Integration responsibility not the Middleware test team's responsibility - All the Middleware had to do was prove the Middleware component was fit-for-purpose through the Test Harness, which was available to customers and application providers to use.
At the Driver / Platform level Interface, the Common-Driver Interface (CDI), we also had a separate Test Harness that also eliminated the need for manual testing (we got pretty close to it). The CDI was much broader than the Middleware because the CDI actually became standard in most customers, even those legacy customers not using Fusion Middleware, instead used HDI (Hardware Driver Interface). HDI was replaced by CDI, as it paved the way to migrating to Fusion in future. So CDI had a customer base much wider than Fusion Middeware, around 30+ platforms. Platforms were therefore subjected to independent testing at CDI, and before promoting to Fusion project, had to be integrated with a known stable GM baseline, pass the acceptance criteria, before merging with mainstream projects.
So our testing strategy relied heavily on discreet testing of features and functionality using various test harnesses depending on which layer was tested. Every Work Package (WP) had an associated Test Specification. The Test Specification consisted of the standard Test Plan which is a collection of Test Scenarios written in plain English to direct the WP Integrators on how to test. Associated every test case is a Technical Streams Specification. This streams specification specifies details of Transport Stream requirements to test the particular test scenario, yes, we hand-crafted bit-streams for each test scenario. Of course some test cases required execution on live stream, but we also had the facility of recording the live broadcast from each night, especially if there's regression on a certain build where test scenarios failed on live, we could go back to that particular date/time and replay that particular broadcast (I think we kept up-to-two weeks old live captures)...The CI system hooked up with the Middleware Test Harness and supplied a control interface to play out bit streams. So when automatically executing a test scenario, one of the first steps was to locate the associated bitstream required for the test, wait for a bitstream player resource to become free, start the bitstream player, wait for a sync point and then execute the tests.
Our Middleware Test Harness had around 1500 tests which were mostly automated, with a few manual tests that stood around 150-200 (it was difficult to simulate Progressive Download environment or a Home Networking setup at the time). This gave us confidence in repeatable, deterministic test cases with a reproducible test environment. This method removed the dependence on having a separate Middleware QA test team, traditionally performing manual testing using some application to drive the Middleware. It was all about solidifying the Middleware Component itself, integrate an application, if some feature was not working, it was most likely an Application error rather than a Middleware error.
All of this was possible through a carefully applied management process, powered by an awesome Continuous Integration platform...
And Finally, I bring thee Continuous Integration: the Mother-of-All CI Systems...
Continuous Integration is about continuously building and testing software, this allows for catching failures early and often, that can be swiftly dealt with. We focused strongly on regression, with daily nightly builds we would spot regressions early. We'd soak the system over the weekends to run the full breadth of tests, especially on delivery of new components such as the platform drivers.
The CI system was a product in its own right. We had a team in the UK that was not only responsible for the product design and development, but the overall supporting hardware infrastructure (hardware was distributed across all the regions) itself. Based on a cluster architecture, with central control residing in the UK, with distributed job servers and workers in located in the local regions, CI jobs could be shared across regions to optimize efficiency. This CI system not only support the mainline product development stream, but also all customer projects. In terms of hardware, apart from the servers implementing the service, the workers were actually real set-top-box units, i.e. STB racks. We had rack and racks of them, STB-farms representing the product baseline hardware (the generic platform which most development was based on), as well as target hardware for each customer project. During my time, the number of STBs connected to the CI system last stood at a count of 400 and was growing (two years back). The CI system of course came with its own management system and access control, priorities could be bumped up for projects as required, tests could be postponed in favour of others, etc.
Of vital importance was the feature of reporting and regression management. The CI portal was central to management as it offered real-time status of the quality of the product. Reporting and tracking defects was therefore essential. You can of course guess we had our own internal Regressions Tracker tool, that became itself another product of the CI team. With the Regression tracker, management could drill down to any project on any hardware and see the results of the latest run. We ran regular regressions meetings to track progress of fixing the regressions. We had all sorts of testing groups, the obvious one being Sanity - When sanity failed, we essentially stopped to fix it immediately (i.e. not the whole project, just the offending component team).
The figure below summarizes most of the above discussion:

Component Owners would regularly monitor their CI reports on each target platform. The criteria for delivering Work Packages depended on component test results all green. An example scenario is shown below of what the CI Dashboard would look like (this is a reconstruction, this was all web-based). This is just a simplified view. Remember as Development owner for the Middleware stack, we had to regularly review the state of all 80+ components, against the various quality criteria. With the RAG status showing Failures (Red) and Passes (Green), it immediately highlighted areas of concern, a failure in any one of the criteria resulted in the component marked Red.
As highlighted earlier, we stressed on Regression. So we had a Regression Tracker that looked something like this:
The Regression Tracker was a powerful tool. The CI system maintained database of all test results for a multitude of builds. We could select different views for comparing the health between different projects. In this example, we are comparing the following test results:
Delivery & Release Management
 |
| Sample CI Dashboard showing Component Test Results |
| Sample Regression Tracker View |
- Test Results as executed on the Grand Master Baseline 12.5 (Current) on Reference Hardware
- The same GM build 12.5 using the BSkyB Target Hardware
- The same test results run on the last baseline on the BSkyB Branch for Launch
- Comparative results on a Work Package stream currently being worked on, e.g. WP4 stream
The Regression Tracker (RT) shows test results for multiple runs, in this example, we executed the test cases five times. On each execution we produce a pass or fail result (shown as Green or Red). Each failure needs to be investigated, so the status is tracked, along with the Owner who's responsible for following through on the action (this could be the Integration Manager or Development Manager), the offending Component, and a Description of the latest comments. All of this is linked to the central Defect Management Tool for tracking purposes. The CI system was able to located failures down to individual STB location, especially useful when we failure to point the source of blame to software, usually pointing to faulty hardware - where the same test case would run on multiple boxes but would only fail on just one particular STB, or a handful of boxes specific to a certain location.
With this strong visualisation tool in-hand, Senior Management had at their fingertips all the information they needed with varying degrees of detail, to help gauge the health of the entire product line-up and customer projects status, all easily accessible on-line, through a simple web-interface.
Delivery & Release Management
The theme of Delivery/Release management is discussed at various places in this post. This section discusses the overall philosophy of the Product's Operational Management goals which drove through the processes that we implemented as described earlier.
The over arching goal was to ensure that all code and feature development was maintained centrally on the Grand Master. All customer projects shared the same GM for as long as possible. Customer branch creation was a matter for serious review, the aim being branch only when necessary, and only as close to Launch Phase as possible. Inherent in the product development/integration processes was always a stable release, stability was always built-in. Doing this therefore reduced the risk and the need for spawning of separate "Stabilisation Streams" for projects, although we had to create this eventually to allow teams to focus on just getting the customer launch out the door. In BSkyB for example, if memory serves me correct, we had branched around three months prior to Launch, a lot of people felt this branch was in fact created too early. We found this out through lessons learnt, feedback from the component teams complained that it became an administration overhead for complex components, which are core to the Middleware providing generic services shared with other customer projects as well, to maintain multiple streams for the same component.
Customer stabilisation branches were allowed but again, this was subject to a few processes:
You might wonder how we managed common feature development on GM to support multiple features for multiple customers without tripping over. That's a topic for another post, suffice to say, the architects designed an innovative way for Tailoring or Configuring the Middleware Stack. Due to its component-based design, the Middleware was able to be configured to suit a variety of combinations, for example, at any point in time, one could generate a Middleware build to suit the following example profiles:
Conclusions
I have attempted to describe the software engineering processes that we adopted in managing a large-scale STB Software delivery project. At first pass, this might seem as an over handed attempt at product management with almost dictatorial control, too much bureaucracy, limiting the freedom and expression of our creative engineers. That is an understandable first take, since I also felt pretty much the same way during my first month on the job. Myself, having just transferred from the Headend Development Group, where as a Senior Engineer was part of a well-formed team that had autonomy to control our own destiny owning a complex IPTV suite of products - we had with little management overheads, freedom of architectural expression and full ownership of product life cycle management. Later on as a Development Manager managing a team of mature senior engineers, executing projects was relatively straightforward as the team was self sufficient. All these teams were of course localised under one roof, no more than seven developers and five testers.
Step into the world of a massively distributed team, a highly critical and visible product initiative and delivery project, and its a different matter altogether! You have to appreciate the context: The company made a firm commitment to a strategy of becoming the world's leading Middleware provider. With an investment to date (as I recall in 2010) of over £50 million British Pounds Sterling (close to a 700 million ZA Rands or 65 million Euros in R&D alone!), the ambition of displacing all existing competitors, this product had very serious overseers banking on its success! It was grand scale product development, and like any manufacturing discipline, at the highest level, we actually created a software factory: with intricate work flows for production and measuring returns. Although this may come as a surprise, engineers did in fact have all the freedom to innovate & be creative within their components and also enhance the architecture, but had to respect the over arching commitments of the business...
Notwithstanding the financial investment in R&D, we were at a stage where this was or 6th or 7th evolution of Middleware - having learnt from all the successes and mistakes of the past, taking in the best design approaches from all Middleware products, and the best architects around the world, we not only settled on a solid architecture, but wanted to establish the best-of-breed software engineering practices in the world. Having had between 3 to 5 years for the processes to establish maturity, and around five years for the architecture to come of age.
Overall investment was between 500-700 people involved in Fusion, in all levels of the STB stack, projects and customer engagements. The project which my posts are based on, consisted of a complement of 200-350 people of that investment.
We implemented Agile methods as best as we could given the above context, when it comes to a distributed development methodology for this kind of work, the following pointers should not be ignored. In fact, IMHO this is regardless of the size of the project, the localisation of teams or the number or complexity of components.
In essence, I think any component development team, before embarking on major STB software project, should take a step back, consider first the best patterns for:
The over arching goal was to ensure that all code and feature development was maintained centrally on the Grand Master. All customer projects shared the same GM for as long as possible. Customer branch creation was a matter for serious review, the aim being branch only when necessary, and only as close to Launch Phase as possible. Inherent in the product development/integration processes was always a stable release, stability was always built-in. Doing this therefore reduced the risk and the need for spawning of separate "Stabilisation Streams" for projects, although we had to create this eventually to allow teams to focus on just getting the customer launch out the door. In BSkyB for example, if memory serves me correct, we had branched around three months prior to Launch, a lot of people felt this branch was in fact created too early. We found this out through lessons learnt, feedback from the component teams complained that it became an administration overhead for complex components, which are core to the Middleware providing generic services shared with other customer projects as well, to maintain multiple streams for the same component.
Customer stabilisation branches were allowed but again, this was subject to a few processes:
- Integration, along with project management decision (after collaboration with the core component owners), had ultimate responsibility for deciding on the timing of branch creation
- Not all components were required to branch
- Adherence to strict product rules:
- All defects fixed during stabilisation phase must first be fixed on the Product GM, then ported to Branch
- No new feature development will ever happen on Customer Branch, new features must happen on GM
- Full traceability of branch fixes: Any component delivering a fix not yet ported to GM raised alarms - unless senior stakeholder gave the approval. Expectation was there should be no more that two or three defects in this state (We had an ClearCase agent that crawled the various project streams looking for defects fixed in component release baselines that were not captured in the GM baseline equivalent)
- Customer branches Die as soon as possible
- As soon as customer launches, there must be a plan to kill off the branch
- There is no merge back to GM!
- This is because all fixes were already on GM anyway
- CI tracked regressions, so customer has confidence in stability is the same on GM, if not better than branch
- Regressions on Customer Branch (during critical stage) took priority
- If we found the customer branch has regressed and GM hasn't - then priority was given to remedial the branch a.s.a.p
- Components with more than one customer branch
- Component owners must inform other projects if a defect on one customer project is found that potentially impacts another customer project
- Customer priorities might influence the scheduling of the fix
 |
| Overview of Branch/Release Strategy |
- Simple SD Zapper with one Tuner
- HD Zapper with two tuners, one primary tuner, one dead (for future PVR use)
- HD PVR with two tuners but no hard disk, a.k.a. Diskless PVR
- HD PVR with USB Support
- Home Gateway Server with 8 tuner support with home networking with local disk
- Home Gateway Server with 8 tuner support with home networking with Network disk
- Gateway client Zapper with PVR support
- Client Zapper without PVR (basic zapper)
- Hybrid-IP box with two tuners, IP plus a third Terrestrial Tuner
- ...
Through well crafted build scripts and a strong design philosophy, we could support any combination of profiles and expose a build to the same level of automated testing. Not only was the Middleware code tailor-able, but also the associated test harnesses.
Very heavy-handed indeed, a lot of collaboration a coordination required at all levels. And we had to balance all those quality best practices against meeting the demands of some really powerful and strong-willed customers! Our customers appreciated this philosophy and saw the obvious gains of benefiting from new features from other projects at a reduced cost, win-win!
We took this profile-based approach of Middleware to our Product UI as well. Once the Middleware gained solid footing, next on the agenda was creating a standard Fusion User Interface application, a.k.a. Snowflake User Experience. Not all PayTV operators take the plunge like BSkyB did to implement their own UI. What we therefore offered to new customers was the Snowflake UX that could be customized in pretty much the same way as Middleware. Depending on the profile of the platform, the UI components could easily be switched on or off, screens and workflows changed to suit the whims and fancies of any marketing department....again, I have a lot to say on this, a subject for another post!
Conclusions
I have attempted to describe the software engineering processes that we adopted in managing a large-scale STB Software delivery project. At first pass, this might seem as an over handed attempt at product management with almost dictatorial control, too much bureaucracy, limiting the freedom and expression of our creative engineers. That is an understandable first take, since I also felt pretty much the same way during my first month on the job. Myself, having just transferred from the Headend Development Group, where as a Senior Engineer was part of a well-formed team that had autonomy to control our own destiny owning a complex IPTV suite of products - we had with little management overheads, freedom of architectural expression and full ownership of product life cycle management. Later on as a Development Manager managing a team of mature senior engineers, executing projects was relatively straightforward as the team was self sufficient. All these teams were of course localised under one roof, no more than seven developers and five testers.
Step into the world of a massively distributed team, a highly critical and visible product initiative and delivery project, and its a different matter altogether! You have to appreciate the context: The company made a firm commitment to a strategy of becoming the world's leading Middleware provider. With an investment to date (as I recall in 2010) of over £50 million British Pounds Sterling (close to a 700 million ZA Rands or 65 million Euros in R&D alone!), the ambition of displacing all existing competitors, this product had very serious overseers banking on its success! It was grand scale product development, and like any manufacturing discipline, at the highest level, we actually created a software factory: with intricate work flows for production and measuring returns. Although this may come as a surprise, engineers did in fact have all the freedom to innovate & be creative within their components and also enhance the architecture, but had to respect the over arching commitments of the business...
Notwithstanding the financial investment in R&D, we were at a stage where this was or 6th or 7th evolution of Middleware - having learnt from all the successes and mistakes of the past, taking in the best design approaches from all Middleware products, and the best architects around the world, we not only settled on a solid architecture, but wanted to establish the best-of-breed software engineering practices in the world. Having had between 3 to 5 years for the processes to establish maturity, and around five years for the architecture to come of age.
Overall investment was between 500-700 people involved in Fusion, in all levels of the STB stack, projects and customer engagements. The project which my posts are based on, consisted of a complement of 200-350 people of that investment.
We implemented Agile methods as best as we could given the above context, when it comes to a distributed development methodology for this kind of work, the following pointers should not be ignored. In fact, IMHO this is regardless of the size of the project, the localisation of teams or the number or complexity of components.
In essence, I think any component development team, before embarking on major STB software project, should take a step back, consider first the best patterns for:
- Configuration Management - You must have a reliable, error-free and efficient mechanism for SCM
- Continuous Integration, Test & Delivery - If you're doing Agile and don't have continuous testing (with automation), you're kidding yourself.
- Software Development Processes - Take time to establish a process that'll work, scale and prove maturity & capability in the long run (of course, Agile is about inspecting & adapting). Avoid collecting technical debt unnecessarily. Appreciate quality control always - don't wait to be be feature development complete then start worrying about quality, this is self-defeating and breaks the very tenet of agile of delivering working functionality every iteration.
- Branch & Release Management - is almost independent from development. Time should be taken to carefully understand your delivery requirements of your customers. Find a pattern that suits not only the team, but also respects the project's expectations. Overhead of administration must not be under estimated.
No comments:
Post a Comment